【微経験エンジニア】の職務経歴書|実務1〜2年のエンジニアが職務経歴書で詰まる3つの理由と書き方
ショクレキ代行
ショクレキ代行

「サーバー・ネットワーク・クラウドを幅広く担当してきたのに、職務経歴書にどう書けばいいかわからない」「インフラは裏方だから、アピールしにくい気がする」インフラエンジニアの転職活動でよく聞く悩みです。システムの安定稼働を支え、クラウド移行やインフラ改善を推進してきた経験は確かな実力なのに、それを採用担当者に伝わる書き方ができていない方がほとんどです。
書類が通らない原因の多くは、「何をしたか」は書けていても「どんな規模のシステムで・どんな技術課題を解決し・どんな成果を出したか」が伝わっていないことにあります。採用担当者はインフラエンジニアの職務経歴書を通じて「システムを安定させながら改善できるか」「クラウドとオンプレを理解してインフラを設計・運用できるか」を判断しています。
この記事では、インフラエンジニアが書類通過率を上げるための職務経歴書の書き方を、差がつく具体的なポイントとともに解説します。
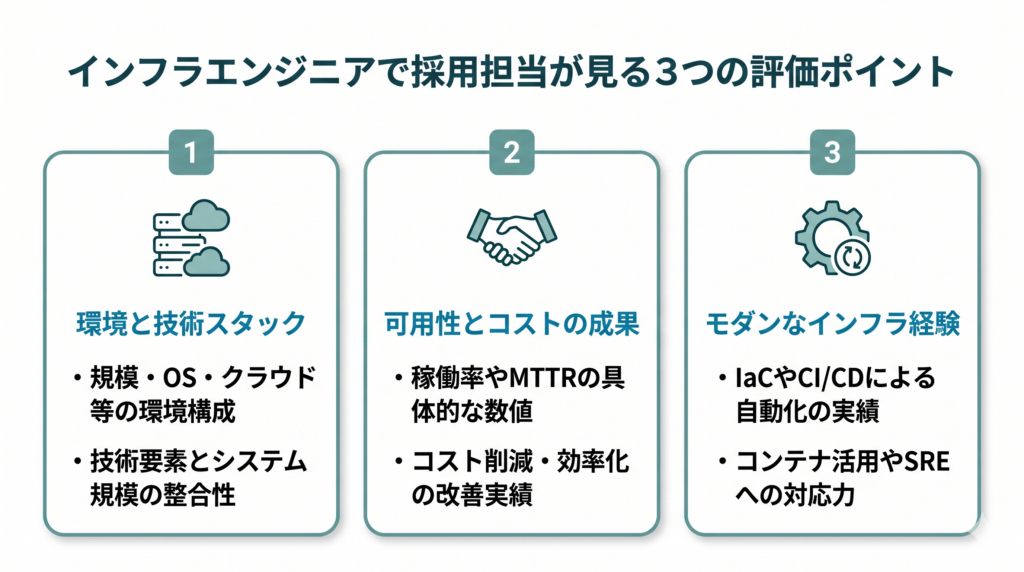
インフラエンジニアの採用担当者が職務経歴書で確認しているのは、主に次の3点です。
| 観点 | 内容 |
| どんな規模・環境のインフラを担当してきたか | サーバー台数・ユーザー数・トラフィック規模・オンプレ/クラウド/ハイブリッドの環境と、使用した技術スタック(OS・仮想化・ネットワーク・クラウドサービス)を確認している |
| 可用性・コスト・パフォーマンスへの改善実績があるか | 稼働率・MTTR・コスト削減額・パフォーマンス改善数値など、インフラ改善の成果を数字で見ている |
| IaCや自動化など現代的なインフラ管理の経験があるか | Terraform・Ansible・CI/CD・コンテナ(Docker・Kubernetes)などのモダンなインフラ管理の経験を確認している |
「Linux・Windows Server・VMware・AWS・GCP・Cisco・Juniper・Docker・Kubernetes・Terraform・Ansible…」と並べるだけでは、実際にどんなシステムでどう使ったかが伝わりません。技術とシステム規模・成果の対応関係を書くことが重要です。
「サーバー・ネットワーク・クラウドの管理・運用を担当してきました」という記述では、採用担当者には実力が判断できません。「オンプレミスからAWSへの移行を主導し、インフラコストを年間約40%削減した」「監視体制の整備とRunbook作成によりMTTRを120分から15分に短縮した」のような改善実績を書くことが重要です。
「サーバーの管理・運用を担当しました」という記述では、1台なのか500台なのかが判断できません。「オンプレ物理サーバー約200台・VM約500台の管理」「月間APIリクエスト数約10億件を処理するAWSインフラの運用」のように規模感を示す数字を入れることで、経験の重さが伝わります。
「オンプレミス(物理サーバー約150台・VM約400台)とAWS(EC2・RDS・S3・CloudFront)のハイブリッド環境を4名体制で管理。ネットワーク(Cisco・Juniper)・仮想化(VMware vSphere)・クラウド(AWS)を担当」のように、管理規模・環境・主要技術スタックをまとめて書くことで採用担当者が業務の全体像をつかめます。
「本番環境の可用性99.95%を2年間維持」「障害発生時のMTTRを120分→18分に短縮(Runbook整備・オンコール体制の最適化)」「AWSへの移行でオンプレコストを年間約3,500万円から約2,000万円に削減(約43%削減)」のように、インフラの成果を数字で書くことで実力が伝わります。
「TerraformでAWSインフラ全体をコード管理し、環境複製時間を2週間→1日に短縮」「AnsibleによるサーバーセットアップをIaC化し、構成ドリフトをゼロに維持」「GitHub ActionsによるCI/CDパイプラインの整備でデプロイ頻度を週1回→日次に向上」のように、IaCや自動化への取り組みを書くことで、モダンなインフラへの適応力が伝わります。
オンプレミスでの「ネットワーク・サーバー・仮想化の深い知識」は、クラウドエンジニアとして非常に高く評価される基礎です。「オンプレの深い知識を持ちながらクラウドに移行できる人材」として、個人での学習実績(AWS資格取得・個人AWSアカウントでの環境構築経験)を合わせてアピールしましょう。
守秘義務を守りながら「業種・システム規模・担当したインフラの種類・使用技術・成果」で記述しましょう。「大手製造業向け生産管理システム(ユーザー数約2,000名)のサーバー・ネットワーク管理を担当。冗長化設計を主導し稼働率99.9%を維持した」のような形式で書けば十分伝わります。
ITサービス企業(従業員数約500名)の社内インフラチーム(4名体制)に所属。オンプレミスサーバー管理・AWS運用・ネットワーク管理を担当。
【業務内容】
・オンプレミスサーバー(物理40台・VM約120台)の管理・運用(Linux/Windows Server)
・AWSインフラの運用(EC2・RDS・S3・CloudFront・Route 53)
・ネットワーク管理(Cisco・FortiGate:VLAN設計・VPN管理・ファイアウォール設定)
・監視設定・アラート管理(Zabbix・CloudWatch)
・障害対応・ポストモーテムの実施
・Terraformを使ったAWSリソースのIaC化(推進中)
【実績・取り組み】
・オンプレ→AWS移行(対象:社内Webシステム3本)を担当メンバーとして参画。移行後のインフラコストを年間約2,800万円から約1,600万円に削減(約43%削減)
・Zabbixアラートのチューニングを実施し、誤検知アラートを月平均200件→40件に削減(On-call品質の向上)
・TerraformでのAWSリソースのIaC化を進め、現在約60%のリソースをコード管理(残り40%を推進中)
・障害時のRunbook整備を担当し、MTTRを平均90分→35分に短縮
自己PRでのアピールポイント
オンプレとAWSの両方を実務で担い、移行プロジェクトとIaC化に携わってきた経験がある。「運用しながら改善する」習慣を持ち、アラート精度の向上とRunbook整備でMTTRを短縮してきた実績を次の職場でも活かしたい。
SaaS企業(ARR約20億円・ユーザー数約50,000社)のインフラチームリード(5名体制)として勤務。AWSインフラ全体の設計・構築・運用と、信頼性エンジニアリング(SRE)の推進を担当。
【業務内容】
・AWSインフラ全体の設計・構築・運用(EKS・RDS Aurora・ElastiCache・CloudFront・WAF)
・TerraformによるIaC化の全社展開(全リソースのコード管理・Atlantisでのレビュープロセス整備)
・SLO設定・エラーバジェット管理・信頼性改善の推進(SREプラクティスの導入)
・CI/CDパイプラインの設計・整備(GitHub Actions・ArgoCD)
・コスト最適化:AWSコストの継続的な最適化(Savings Plans・スポットインスタンス活用)
・インフラチームメンバー4名の技術指導・コードレビュー
【実績】
・サービスの可用性:SLO 99.95%を12ヶ月連続で達成
・AWSコストを年間で約22%削減(Savings Plans導入・不要リソースの整理・スポットインスタンス活用)
・EKSへのコンテナ移行を主導し、デプロイ頻度を月4回→日次(約20回/月)に向上
・障害発生時のMTTRを90分→12分に短縮(Runbook整備・PagerDutyとの連携・自動ロールバックの実装)
・TerraformのIaC化率を20%→95%に向上(1年間で達成)
【主な取り組み】
SLO達成の鍵は「エラーバジェットの可視化」にあった。各サービスのエラーレートをDatadogでリアルタイムモニタリングし、エラーバジェットの消費速度をチームで週次確認する文化を定着させた。EKSへの移行はブルーグリーンデプロイの整備と自動ロールバックを同時に実装し、移行後の本番障害件数をゼロにした。
自己PRでのアピールポイント
AWSインフラの設計・IaC化・SRE推進・コスト最適化を一気通貫で担ってきた経験がある。「信頼性とデリバリー速度を同時に高める」インフラ設計の思想を次の職場でも実践したい。
東証プライム上場のIT企業(従業員数約2,000名)のインフラ部門マネージャーとして勤務。インフラチーム15名のマネジメントと、全社インフラ戦略(クラウドシフト・ゼロトラスト・インフラコスト最適化)の立案・推進を担当。
【業務内容】
・インフラチーム15名のマネジメント(採用・評価・育成・目標設定)
・全社インフラ戦略の立案・ロードマップ策定・経営陣への報告
・マルチクラウド(AWS・GCP)環境の統括・コスト管理(年間インフラ予算:約5億円)
・ゼロトラストアーキテクチャへの移行プロジェクトの統括
・SREプラクティスの全社展開・SLO文化の醸成
・ベンダー(AWS・GCP)との関係管理・エンタープライズ契約の交渉
【実績】
・インフラコストを3年間で年間5億円→3億円(約40%削減)。クラウドリザーブドインスタンス・Savings Plansの最適活用・不要リソース整理・マルチクラウド最適化による
・全社サービスの可用性(SLO)99.9%以上を2年連続達成(インシデント件数は前年比60%削減)
・ゼロトラスト移行を主導し、セキュリティインシデントによる業務停止時間をゼロに維持(移行後2年間)
・インフラチームのMTTR:組織平均60分→10分に短縮(SREプラクティス・Runbook整備・オンコール体制最適化)
【主な取り組み】
インフラコスト削減は「コストの可視化」から着手し、サービス・チーム・リソース種別ごとのコスト分析ダッシュボードをKubecostとAWS Cost Explorerで整備した。「なんとなく多い」から「どのサービスが・なぜ高いか」が明確になったことで、削減施策の優先順位が立てやすくなった。SREの全社展開では、インフラチームのSREノウハウをSREガイドブックとして整備し、開発チームが自律的にSLOを設定・運用できる体制をつくった。
自己PRでのアピールポイント
インフラの実務からチームマネジメント・全社インフラ戦略の立案・コスト最適化・ゼロトラスト推進まで幅広く担ってきた。「インフラをビジネスの競争力として位置づけ、コスト・可用性・セキュリティを同時に最適化する」視点を持ち、次の職場でも貢献したい。
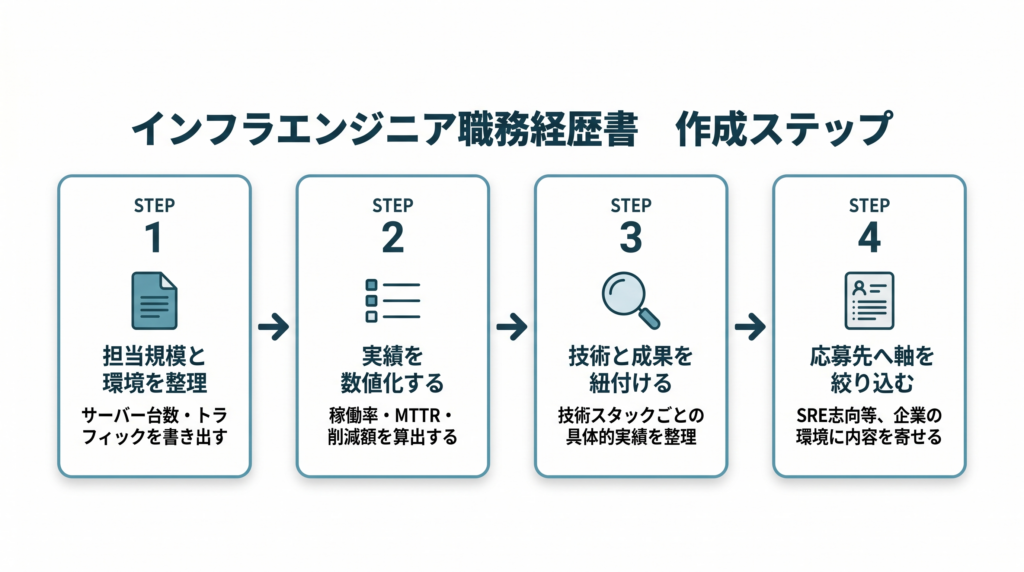
担当してきたインフラ環境の規模感を数字で整理します。「物理サーバー○台・VM○台・月間トラフィック○GB・ユーザー数○万人・AWS/GCP/Azure の使用サービス一覧」など、採用担当者が規模感を即座に把握できる情報を書き出しましょう。
稼働率(SLA達成率)・MTTR(平均復旧時間)・クラウドコスト削減額・デプロイ頻度・IaC化率・障害件数削減など、成果として数字で表現できるものをすべて書き出します。完璧な数字でなくても概数で構いません。
「技術名・経験年数・習熟度(業務レベル/設計可能/チーム導入実績あり)・主な使用プロジェクト」の4項目でスキルシートを作成します。OS・ネットワーク・クラウド・仮想化・監視・CI/CD・IaCの各カテゴリに分けて整理すると採用担当者が読みやすくなります。
応募先のインフラ環境(オンプレミス重視・クラウドネイティブ・ハイブリッド・SRE組織)を事前に調べ、自分の経験の中から最もマッチする部分を前面に出します。同じ経歴でもアピール軸を変えることで通過率が大きく変わります。
失敗①:技術スタックの羅列で終わっている
失敗②:規模感がない
失敗③:可用性・MTTR・コスト削減の実績が書かれていない
失敗④:IaC・自動化への取り組みが書かれていない
「管理規模・技術スタックの使用実績・改善への取り組み(Runbook整備・アラートチューニング・IaC化)」が評価のポイントです。大きな実績がなくても「自分から課題を発見して改善した経験」を1〜2つ具体的に書くことで主体性が伝わります。
「クラウド移行・IaC化・SRE推進などのモダンインフラ改善の実績」「可用性・MTTR・コスト改善の数字」「チームへの貢献(コードレビュー・育成)」が評価の軸になります。「なぜその技術選択をしたか」の設計判断の理由を書くことで差別化できます。
インフラ部門のマネジメント・インフラ戦略の立案・コスト最適化・セキュリティ戦略(ゼロトラスト)・経営陣との連携が最大のアピールポイントです。「チーム人数・年間インフラコスト削減額・可用性の達成実績・MTTR改善」など、組織全体のインフラ力を高めてきた実績を中心に書きましょう。
可能です。インフラエンジニアでの「システムの可用性管理・障害対応・コスト管理の経験」はSREに直接活きます。SLO設定・エラーバジェット・自動化への取り組みを積極的にアピールしましょう。
オンプレの深い知識はクラウドで差別化できる強みです。AWSやGCPの資格取得・個人アカウントでの環境構築実績を合わせてアピールしましょう。
「可用性99.9%以上を○年間維持」「MTTRを約○%短縮」など概数・変化率での表現で構いません。「約」をつけて書けば問題ありません。
インフラエンジニアはスキルシート込みで3〜4枚が目安です。管理規模・技術スタック・可用性・MTTR・コスト削減などの核心情報を優先して記載しましょう。
応募先のポジションに合わせてアピール軸を調整しましょう。インフラエンジニアの求人なら「可用性・コスト・パフォーマンス」を前面に出し、セキュリティ経験は「インフラセキュリティへの理解が深い」という補足でアピールするのが効果的です。
インフラエンジニアの経験は正しく書けば必ず評価されます。まずは管理しているサーバー台数・可用性・MTTR・コスト削減の数字を書き出すところから始めてみてください。
ここまで読んで「書き方の型はわかったけれど、いざ自分のことになると手が止まる」と感じた方もいるかもしれません。職務経歴書は、自分の経験を客観的に整理する作業がいちばんの壁です。
ショクレキでは、採用・キャリア支援の経験者がヒアリングをもとに、あなたの経験を一緒に言語化して職務経歴書として仕上げます。書類選考が通らずに悩んでいる方も、自分では気づいていない強みが見つかることが多いので、まずはお気軽にご相談ください。